


Aquiles-Image is a production-ready API server that lets you run state-of-the-art image generation models on your own infrastructure. OpenAI-compatible by design, you can switch from external services to self-hosted in under 5 minutes.
| Challenge | Aquiles-Image Solution |
|---|---|
| 💸 Expensive external APIs | Run models locally with unlimited usage |
| 🔒 Data privacy concerns | Your images never leave your server |
| 🐌 Slow inference | Advanced optimizations for 3x faster generation |
| 🔧 Complex setup | One command to run any supported model |
| 🚫 Vendor lock-in | OpenAI-compatible, switch without rewriting code |
- 🔌 OpenAI Compatible - Use the official OpenAI client with zero code changes
- ⚡ Intelligent Batching - Automatic request grouping by shared parameters for maximum throughput on single or multi-GPU setups
- 🎨 30+ Optimized Models - 18 image (FLUX, SD3.5, Qwen) + 12 video models (Wan2.x, HunyuanVideo) + unlimited via AutoPipeline (Only T2I)
- 🚀 Multi-GPU Support - Distributed inference with dynamic load balancing across GPUs (image models) for horizontal scaling
- 🛠️ Superior DevX - Simple CLI, dev mode for testing, built-in monitoring
- 🎬 Advanced Video - Text-to-video with Wan2.x and HunyuanVideo series (+ Turbo variants)
- 🧩 LoRA Support - Load any LoRA from HuggingFace or a local path via a simple JSON config file, compatible with all native models and AutoPipeline
# From PyPI (recommended)
pip install aquiles-image
# From source
git clone https://github.com/Aquiles-ai/Aquiles-Image.git
cd Aquiles-Image
pip install .Single-Device Mode (Default)
aquiles-image serve --model "stabilityai/stable-diffusion-3.5-medium"Multi-GPU Distributed Mode (Image Models Only)
aquiles-image serve --model "stabilityai/stable-diffusion-3.5-medium" --dist-inferenceDistributed Inference Note: Enable multi-GPU mode by adding the
--dist-inferenceflag. Each GPU will load a copy of the model, so ensure each GPU has sufficient VRAM. The system automatically balances load across GPUs and groups requests with shared parameters for maximum throughput.
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:5500", api_key="not-needed")
result = client.images.generate(
model="stabilityai/stable-diffusion-3.5-medium",
prompt="a white siamese cat",
size="1024x1024"
)
print(f"Image URL: {result.data[0].url}")That's it! You're now generating images with the same API you'd use for OpenAI.
stabilityai/stable-diffusion-3-mediumstabilityai/stable-diffusion-3.5-mediumstabilityai/stable-diffusion-3.5-largestabilityai/stable-diffusion-3.5-large-turboblack-forest-labs/FLUX.1-devblack-forest-labs/FLUX.1-schnellblack-forest-labs/FLUX.1-Krea-devblack-forest-labs/FLUX.2-dev*diffusers/FLUX.2-dev-bnb-4bitTongyi-MAI/Z-Image-TurboQwen/Qwen-ImageQwen/Qwen-Image-2512black-forest-labs/FLUX.2-klein-4Bblack-forest-labs/FLUX.2-klein-9Bzai-org/GLM-Image- (This model is usually the slowest to execute in relative terms)Tongyi-MAI/Z-Imageblack-forest-labs/FLUX.2-klein-9b-kvNucleusAI/Nucleus-Image
black-forest-labs/FLUX.1-Kontext-devdiffusers/FLUX.2-dev-bnb-4bit- Supports multi-image editing. Maximum 10 input images.black-forest-labs/FLUX.2-dev* - Supports multi-image editing. Maximum 10 input images.Qwen/Qwen-Image-EditQwen/Qwen-Image-Edit-2509- Supports multi-image editing. Maximum 3 input images.Qwen/Qwen-Image-Edit-2511- Supports multi-image editing. Maximum 3 input images.black-forest-labs/FLUX.2-klein-4B- Supports multi-image editing. Maximum 10 input images.black-forest-labs/FLUX.2-klein-9B- Supports multi-image editing. Maximum 10 input images.black-forest-labs/FLUX.2-klein-9b-kv- Supports multi-image editing. Maximum 10 input images.zai-org/GLM-Image- Supports multi-image editing. Maximum 5 input images. (This model is usually the slowest to execute in relative terms)
* Note on FLUX.2-dev: Requires NVIDIA H200.
Text-to-Video and Image-to-Video (Only LTX-2/LTX-2.3 accept T2V and I2V, other models only accept T2V) (/videos)
Wan-AI/Wan2.2-T2V-A14B(High quality, 40 steps - start with--model "wan2.2")Aquiles-ai/Wan2.2-Turbo⚡ 9.5x faster - Same quality in 4 steps! (start with--model "wan2.2-turbo")
Wan-AI/Wan2.1-T2V-14B(High quality, 40 steps - start with--model "wan2.1")Aquiles-ai/Wan2.1-Turbo⚡ 9.5x faster - Same quality in 4 steps! (start with--model "wan2.1-turbo")Wan-AI/Wan2.1-T2V-1.3B(Lightweight version, 40 steps - start with--model "wan2.1-3B")Aquiles-ai/Wan2.1-Turbo-fp8⚡ 9.5x faster + FP8 optimized - 4 steps (start with--model "wan2.1-turbo-fp8")
Standard Resolution (480p)
Aquiles-ai/HunyuanVideo-1.5-480p(50 steps - start with--model "hunyuanVideo-1.5-480p")Aquiles-ai/HunyuanVideo-1.5-480p-fp8(50 steps, FP8 optimized - start with--model "hunyuanVideo-1.5-480p-fp8")Aquiles-ai/HunyuanVideo-1.5-480p-Turbo⚡ 12.5x faster - 4 steps! (start with--model "hunyuanVideo-1.5-480p-turbo")Aquiles-ai/HunyuanVideo-1.5-480p-Turbo-fp8⚡ 12.5x faster + FP8 optimized - 4 steps (start with--model "hunyuanVideo-1.5-480p-turbo-fp8")
High Resolution (720p)
Aquiles-ai/HunyuanVideo-1.5-720p(50 steps - start with--model "hunyuanVideo-1.5-720p")Aquiles-ai/HunyuanVideo-1.5-720p-fp8(50 steps, FP8 optimized - start with--model "hunyuanVideo-1.5-720p-fp8")
Lightricks/LTX-2(40 steps - start with--model "ltx-2")Lightricks/LTX-2.3(40 steps - start with--model "ltx-2.3")
Special Features: LTX-2/LTX-2.3 are the first open-sources models supporting synchronized audio-video generation in a single model, comparable to closed models like Sora-2 and Veo 3.1. Additionally, LTX-2 supports image input as the first frame of the video - pass a reference image via
input_referenceto guide the visual starting point of the generation. For best results with this model, please follow the prompts guide provided by the Lightricks team.
Image-to-Video example:
curl -X POST "https://YOUR_BASE_URL_DEPLOY/videos" \
-H "Authorization: Bearer dummy-api-key" \
-H "Content-Type: multipart/form-data" \
-F prompt="She turns around and smiles, then slowly walks out of the frame." \
-F model="ltx-2" \
-F size="1280x720" \
-F seconds="8" \
-F input_reference="@sample_720p.jpeg;type=image/jpeg"VRAM Requirements: Most models need 24GB+ VRAM. All video models require H100/A100-80GB. FP8 optimized versions offer better memory efficiency.
📖 Full models documentation and more models in 🎬 Aquiles-Studio
If the model you need isn't in our native list, you can still run virtually any architecture based on Diffusers (SD 1.5, SDXL, etc.) using our AutoPipeline implementation.
Check out the 🧪 Advanced Features section to learn how to deploy any Hugging Face model with a single command.
aquiles-image-demo.mp4
fluxdemo.mp4
| Input + Prompt | Result |
|---|---|
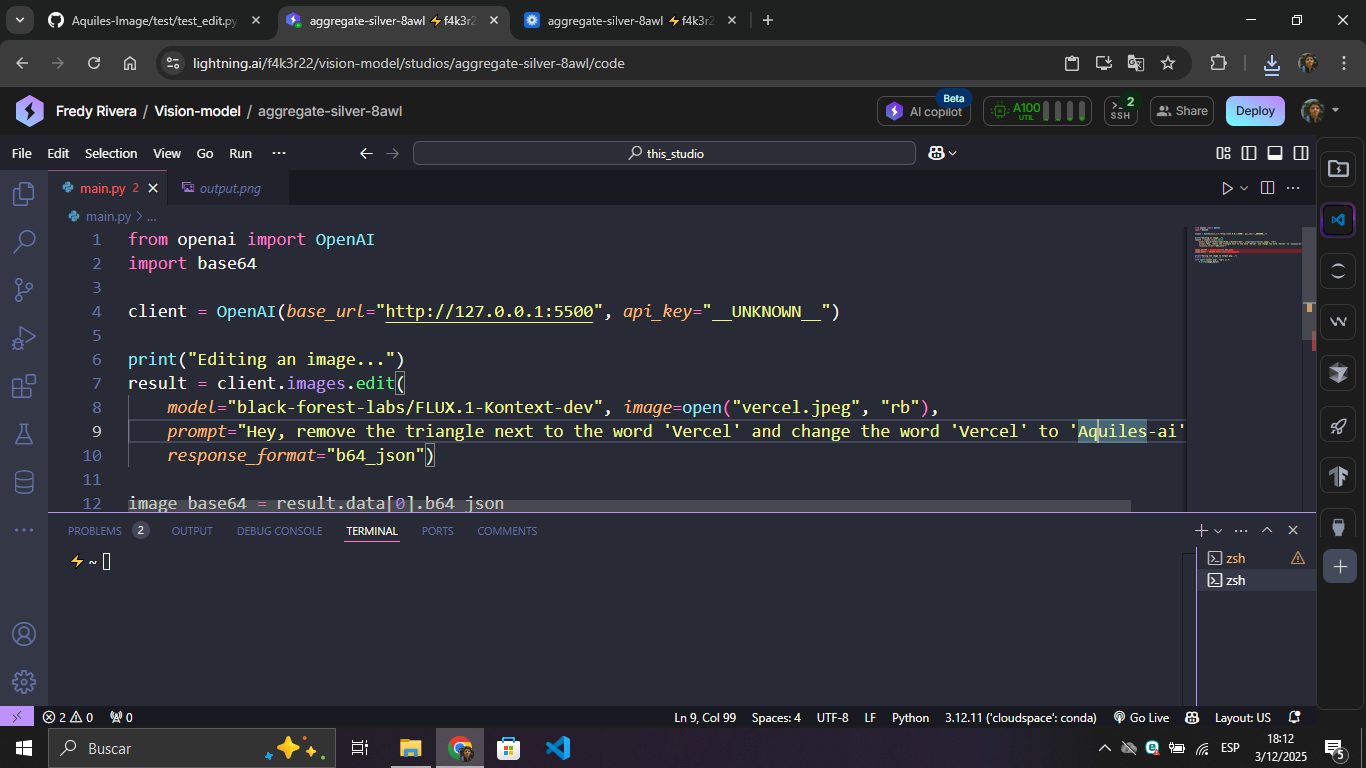 |
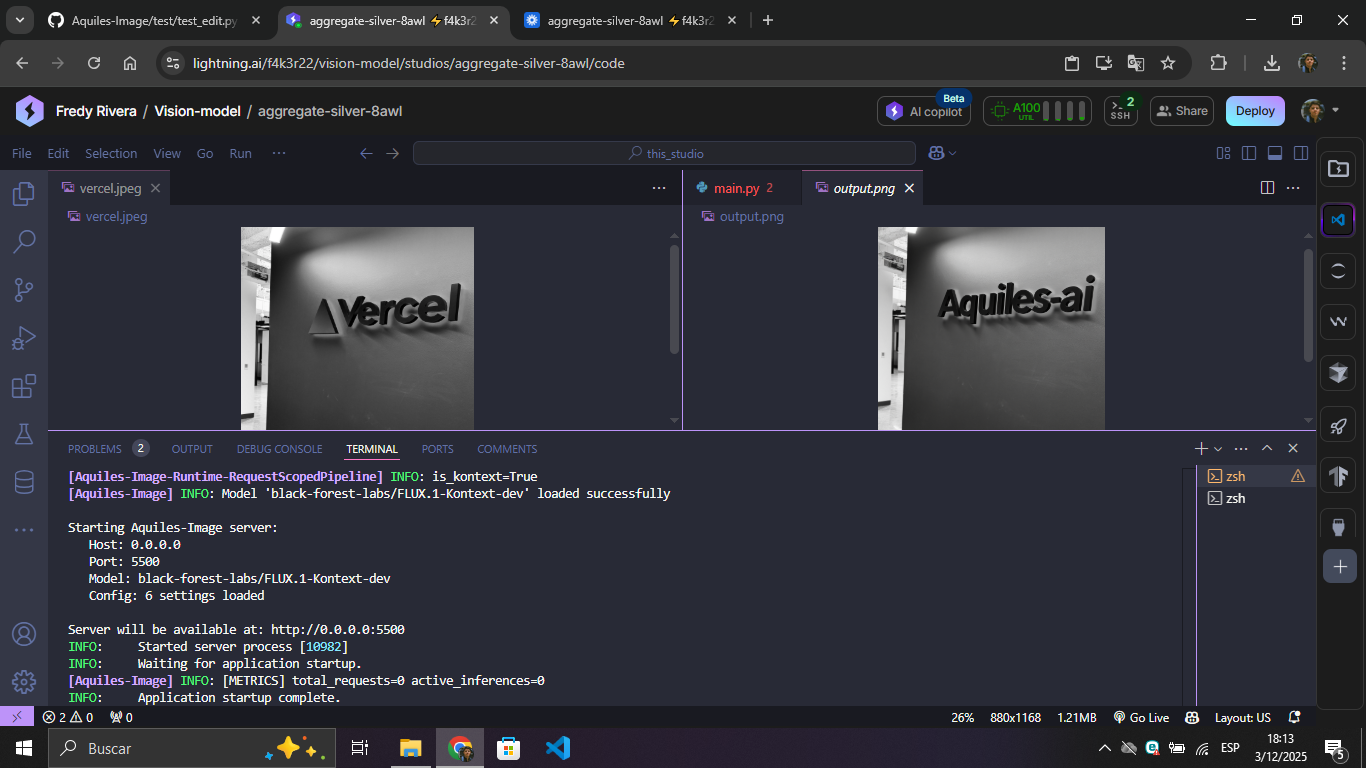 |
video.mp4
Note: Video generation with
wan2.2takes ~30 minutes on H100. Withwan2.2-turbo, it takes only ~3 minutes! Only one video can be generated at a time.
Video and audio generation
ltx_2.mp4
Run any model compatible with AutoPipelineForText2Image or AutoPipelineForImage2Image from HuggingFace:
aquiles-image serve \
--model "stabilityai/stable-diffusion-xl-base-1.0" \
--auto-pipeline \
--set-steps 30 \
--auto-pipeline-type t2i # or i2i for Image to ImageSupported models include:
stable-diffusion-v1-5/stable-diffusion-v1-5stabilityai/stable-diffusion-xl-base-1.0- Any HuggingFace model compatible with
AutoPipelineForText2ImageorAutoPipelineForImage2Image
Trade-offs:
⚠️ Slower inference than native implementations⚠️ Experimental - may have stability issues
Load any LoRA from HuggingFace or a local path by passing a JSON config file at startup. Compatible with all native image models and AutoPipeline.
1. Create a LoRA config file:
Manually:
{
"repo_id": "brushpenbob/Flux-retro-Disney-v2",
"weight_name": "Flux_retro_Disney_v2.safetensors",
"adapter_name": "flux-retro-disney-v2",
"scale": 1.0
}Or programmatically using the Python helper:
from aquilesimage.utils import save_lora_config
from aquilesimage.models import LoRAConfig
save_lora_config(
LoRAConfig(
repo_id="brushpenbob/Flux-retro-Disney-v2",
weight_name="Flux_retro_Disney_v2.safetensors",
adapter_name="flux-retro-disney-v2"
),
"./lora_config.json"
)2. Start the server with LoRA enabled:
aquiles-image serve \
--model "black-forest-labs/FLUX.1-dev" \
--load-lora \
--lora-config "./lora_config.json"Works in both single-device and distributed mode:
aquiles-image serve \
--model "black-forest-labs/FLUX.1-dev" \
--load-lora \
--lora-config "./lora_config.json" \
--dist-inferencePerfect for development, testing, and CI/CD:
aquiles-image serve --no-load-modelWhat it does:
- Starts server instantly without GPU
- Returns test images that simulate real responses
- All endpoints functional with realistic formats
- Same API structure as production
You can protect your server by requiring an API key on every request. Simply pass --api-key when starting the server:
aquiles-image serve --model "stabilityai/stable-diffusion-3.5-medium" --api-key "your-api-key"All requests must then include the key in the Authorization header:
curl -X POST "http://localhost:5500/images/generations" \
-H "Authorization: Bearer your-api-key" \
-H "Content-Type: application/json" \
-d '{"model": "stabilityai/stable-diffusion-3.5-medium", "prompt": "a white siamese cat"}'Aquiles-Image ships with a built-in interactive playground for testing image models and monitoring server stats — protected by login to prevent unauthorized access. Enable it with --username and --password:
aquiles-image serve --model "stabilityai/stable-diffusion-3.5-medium" \
--api-key "your-api-key" \
--username "root" \
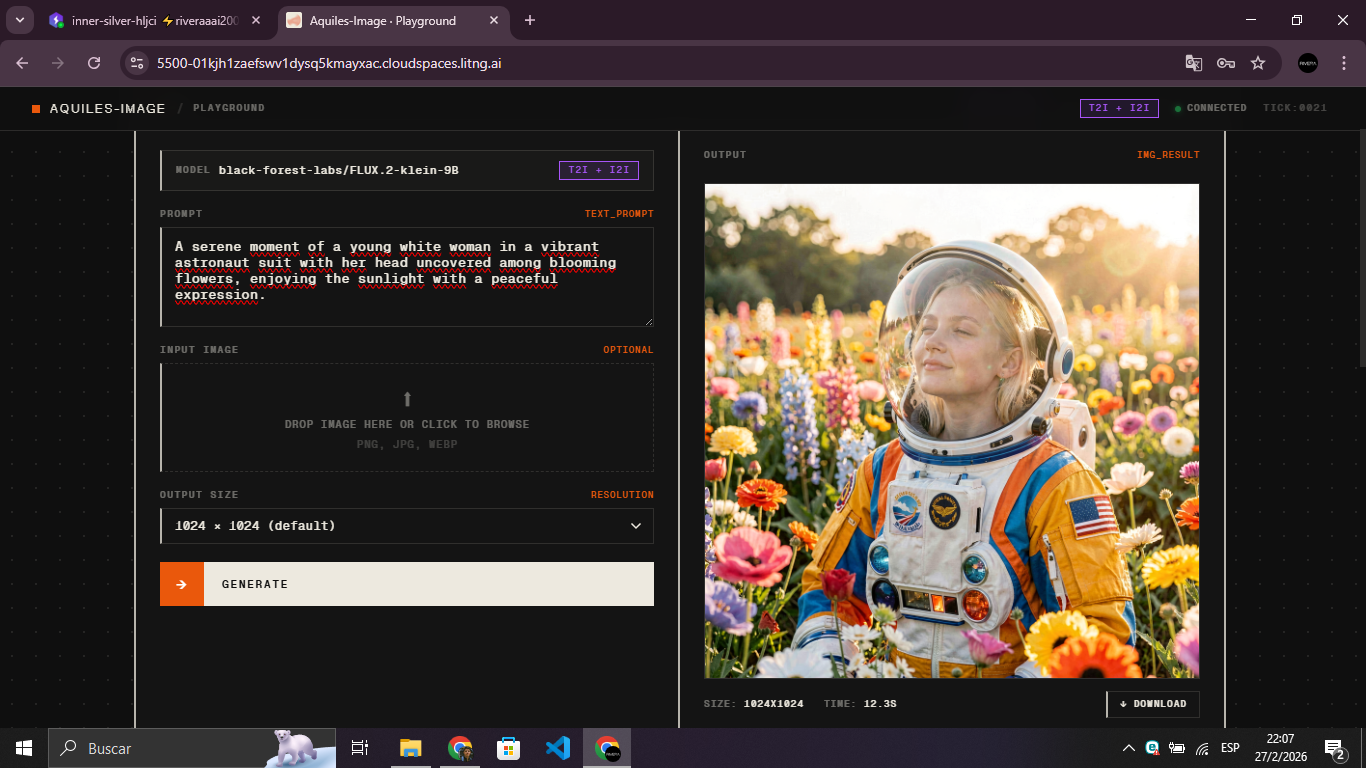
--password "root"Once running, open http://localhost:5500 in your browser. The playground lets you:
- Generate images interactively using any loaded image model
- Visualize server stats in real time
Note: The playground is only available for image models.
Login
Playground
Aquiles-Image provides a custom /stats endpoint for real-time monitoring:
import requests
# Get server statistics
stats = requests.get("http://localhost:5500/stats",
headers={"Authorization": "Bearer YOUR_API_KEY"}).json()
print(f"Total requests: {stats['total_requests']}")
print(f"Total images generated: {stats['total_images']}")
print(f"Queued: {stats['queued']}")
print(f"Completed: {stats['completed']}")The response varies depending on the model type and configuration:
{
"mode": "single-device",
"total_requests": 150,
"total_batches": 42,
"total_images": 180,
"queued": 3,
"completed": 147,
"failed": 0,
"processing": true,
"available": false
}{
"mode": "distributed",
"devices": {
"cuda:0": {
"id": "cuda:0",
"available": true,
"processing": false,
"can_accept_batch": true,
"batch_size": 4,
"max_batch_size": 8,
"images_processing": 0,
"images_completed": 45,
"total_batches_processed": 12,
"avg_batch_time": 2.5,
"estimated_load": 0.3,
"error_count": 0,
"last_error": null
},
"cuda:1": {
"id": "cuda:1",
"available": true,
"processing": true,
"can_accept_batch": false,
"batch_size": 2,
"max_batch_size": 8,
"images_processing": 2,
"images_completed": 38,
"total_batches_processed": 10,
"avg_batch_time": 2.8,
"estimated_load": 0.7,
"error_count": 0,
"last_error": null
}
},
"global": {
"total_requests": 150,
"total_batches": 42,
"total_images": 180,
"queued": 3,
"active_batches": 1,
"completed": 147,
"failed": 0,
"processing": true
}
}{
"total_tasks": 25,
"queued": 2,
"processing": 1,
"completed": 20,
"failed": 2,
"available": false,
"max_concurrent": 1
}Key Metrics:
total_requests/tasks- Total number of generation requests receivedtotal_images- Total images generated (image models only)queued- Requests waiting to be processedprocessing- Currently processing requestscompleted- Successfully completed requestsfailed- Failed requestsavailable- Whether server can accept new requestsmode- Operation mode for image models:single-deviceordistributed
| Who | What |
|---|---|
| 🚀 AI Startups | Build image generation features without API costs |
| 👨💻 Developers | Prototype with multiple models using one interface |
| 🏢 Enterprises | Scalable, private image AI infrastructure |
| 🔬 Researchers | Experiment with cutting-edge models easily |
- Python 3.8+
- CUDA-compatible GPU with 24GB+ VRAM (most models)
- 10GB+ free disk space
We welcome contributions! Whether you want to:
- 🐛 Report bugs and issues
- 🎨 Add support for new image models
- 📝 Improve documentation
Please read our Contributing Guide to get started.
⭐ Star this project • 🐛 Report issues • 🤝 Contribute
Built with ❤️ for the AI community